مطالعات موردی یادگیری عمیق
مطالعات موردی یادگیری عمیق
4 مدل CNN از پیش آموزش دیده برای استفاده از دید رایانه ای با یادگیری انتقال
با استفاده از مدل های شبکه عصبی پیشرفته از پیش آموزش داده شده برای با مشکلات بینایی رایانه ای با یادگیری انتقال
مقابله کنید. قبل از شروع ، اگر این مقاله را می خوانید ، مطمئن هستم که ما علائق مشابهی داریم و در صنایع مشابه قرار داریم/خواهیم بود. بنابراین اجازه دهید از طریق Linkedin متصل شویم! لطفا در ارسال درخواست تماس دریغ نکنید! Orhan G. Yalçın-Linkedin
 شکل 1. چگونه آموزش کار می کند (تصویر توسط نویسنده)
شکل 1. چگونه آموزش کار می کند (تصویر توسط نویسنده) اگر سعی کرده اید مدلهای یادگیری ماشین را با دقت بالا بسازید ؛ اما هرگز آموزش انتقال را امتحان نکرده اید ، این مقاله زندگی شما را تغییر خواهد داد. حداقل ، این کار را با من انجام داد!
اکثر ما قبلاً چندین آموزش یادگیری ماشین را برای درک اصول اولیه شبکه های عصبی امتحان کرده ایم. این آموزش ها برای درک اصول اولیه شبکه های عصبی مصنوعی مانند شبکه های عصبی مکرر ، شبکه های عصبی کانولوشن ، GANs و Autoencoders بسیار مفید بود. اما ، عملکرد اصلی آنها این بود که شما را برای پیاده سازی های دنیای واقعی آماده کنند.
در حال حاضر ، اگر قصد دارید یک سیستم هوش مصنوعی بسازید که از یادگیری عمیق استفاده می کند ، یا (من) باید بودجه بسیار بالایی داشته باشید. برای آموزش و پژوهشگران هوش مصنوعی عالی که در اختیار شماست یا (ii) باید از یادگیری انتقالی بهره مند شوند.
یادگیری انتقال چیست؟
یادگیری انتقال زیر شاخه ای از یادگیری ماشین و هوش مصنوعی است که قصد دارد دانش به دست آمده از یک کار (وظیفه منبع) را در یک کار متفاوت اما مشابه (وظیفه هدف) به کار گیرد.
به عنوان مثال ، دانش به دست آمده در هنگام یادگیری طبقه بندی متون ویکی پدیا می تواند برای مقابله با قانون استفاده شود. مشکلات طبقه بندی متن مثال دیگر استفاده از دانش به دست آمده در هنگام یادگیری طبقه بندی اتومبیل ها برای تشخیص پرندگان در آسمان است. همانطور که می بینید رابطه ای بین این نمونه ها وجود دارد. ما از مدل طبقه بندی متنی برای تشخیص پرندگان استفاده نمی کنیم.
 شکل 2. چرخ را دوباره اختراع نکنید ، دانش موجود را منتقل کنید (عکس توسط جان کارتاگنا در Unsplash)
شکل 2. چرخ را دوباره اختراع نکنید ، دانش موجود را منتقل کنید (عکس توسط جان کارتاگنا در Unsplash) سابقه انتقال یادگیری
برای نشان دادن قدرت یادگیری انتقال ، می توانیم از اندرو نگ نقل قول کنیم:
 شکل 3. انتظار Andrew Ng برای موفقیت تجاریزیرزمینه های یادگیری ماشین (تصویر توسط نویسنده)
شکل 3. انتظار Andrew Ng برای موفقیت تجاریزیرزمینه های یادگیری ماشین (تصویر توسط نویسنده) یادگیری انتقالی چگونه کار می کند؟
سه الزام برای دستیابی به یادگیری انتقال وجود دارد:
توسعه مدل بازآموزش یافته منبع باز
یک مدل از پیش آموزش داده شده مدلی است که توسط شخص دیگری برای حل مشکلی مشابه ما ایجاد و آموزش داده شده است. در عمل ، کسی تقریباً یک غول فناوری یا گروهی از محققان ستاره است. آنها معمولاً یک مجموعه داده بسیار بزرگ را به عنوان مجموعه داده های اصلی خود مانند ImageNet یا Corpus ویکی پدیا انتخاب می کنند. سپس ، آنها یک شبکه عصبی بزرگ (مانند VGG19 دارای 143،667،240 پارامتر) برای حل یک مشکل خاص ایجاد می کنند (به عنوان مثال ، این مشکل طبقه بندی تصویر برای VGG19 است). البته ، این مدل از پیش آموزش داده شده باید عمومی شود تا بتوانیم این مدلها را برداریم و آنها را مجدداً مورد استفاده قرار دهیم. ، ما دانش آموخته شده را مجدداً مورد استفاده قرار می دهیم که شامل لایه ها ، ویژگی ها ، وزن ها و سوگیری ها است. روشهای مختلفی برای بارگذاری یک مدل از پیش آموزش دیده در محیط ما وجود دارد. در نهایت ، این فقط یک فایل/پوشه است که حاوی اطلاعات مربوطه است. با این حال ، کتابخانه های یادگیری عمیق در حال حاضر میزبان بسیاری از این مدل های از پیش آموزش دیده هستند ، که آنها را راحت تر و راحت تر می کند:
برای بارگذاری یک مدل آموزش دیده می توانید از یکی از منابع بالا استفاده کنید. معمولاً با تمام لایه ها و وزن ها همراه است و می توانید شبکه را به دلخواه ویرایش کنید.
تنظیم دقیق مشکل
خوب ، در حالی که ممکن است مدل فعلی برای ما کار کند مسئله. اغلب بهتر است به دو دلیل مدل از پیش آموزش دیده را تنظیم کنیم: قالب صحیح.
به طور کلی ، در یک شبکه عصبی ، در حالی که لایه های پایین و سطح متوسط معمولاً ویژگی های کلی را نشان می دهند ، لایه های بالایی ویژگی های خاص مشکل را نشان می دهند. از آنجا که مشکل جدید ما متفاوت از مشکل اصلی است ، ما تمایل داریم لایه های بالایی را کنار بگذاریم. با افزودن لایه های خاص مشکلات خود ، می توانیم به دقت بالاتری دست یابیم.
پس از حذف لایه های بالا ، باید لایه های خود را قرار دهیم تا بتوانیم خروجی مورد نظر خود را بدست آوریم. به عنوان مثال ، مدلی که با ImageNet آموزش دیده است می تواند تا 1000 شیء را طبقه بندی کند. اگر ما سعی می کنیم ارقام دست نویس را طبقه بندی کنیم (به عنوان مثال ، طبقه بندی MNIST) ، ممکن است بهتر باشد که یک لایه نهایی با تنها 10 نورون به پایان برسد.
پس از افزودن لایه های سفارشی خود به مدل از پیش آموزش دیده ، ما می توانیم آن را با عملکردهای مخصوص از دست دادن و بهینه سازها پیکربندی کنیم و با آموزش اضافی تنظیم کنیم.
4 مدل از پیش آموزش دیده کامپیوتر
در اینجا چهار شبکه از پیش آموزش دیده شده است. می تواند برای کارهای بینایی رایانه ای مانند تولید تصویر ، انتقال سبک عصبی ، طبقه بندی تصویر ، زیرنویس تصویر ، تشخیص ناهنجاری و غیره استفاده کند:
بیایید یک به یک به آنها بپردازیم.
VGG-19
VGG یک شبکه عصبی پیچشی است که دارای عمق19 لایه این برنامه توسط کارن سیمونیان و اندرو زیسرمن در دانشگاه آکسفورد در سال 2014 ساخته و آموزش داده شده است و می توانید به تمام اطلاعات مقاله آنها ، شبکه های تحولی بسیار عمیق برای تشخیص تصویر در مقیاس بزرگ که در سال 2015 منتشر شد دسترسی داشته باشید. VGG-19 شبکه همچنین با استفاده از بیش از 1 میلیون تصویر از پایگاه داده ImageNet آموزش می بیند. به طور طبیعی ، می توانید مدل را با وزنه های آموزش دیده ImageNet وارد کنید. این شبکه از پیش آموزش دیده می تواند تا 1000 شیء را طبقه بندی کند. این شبکه بر روی تصاویر رنگی 224x224 پیکسل آموزش دیده است. در اینجا اطلاعات مختصری در مورد اندازه و عملکرد آن وجود دارد:
 شکل 4. تصویری از شبکه VGG-19 (شکل Clifford K. Yang و Yufeng Zheng در ResearchGate)
شکل 4. تصویری از شبکه VGG-19 (شکل Clifford K. Yang و Yufeng Zheng در ResearchGate) Inceptionv3 (GoogLeNet)
Inceptionv3 یک شبکه عصبی پیچشی است که عمق آن 50 لایه است. این توسط گوگل ساخته و آموزش داده شده است و می توانید به تمام اطلاعات روی کاغذ با عنوان "عمیق تر شدن با پیچیدگی ها" دسترسی پیدا کنید. نسخه از پیش آموزشده Inceptionv3 با وزن ImageNet می تواند تا 1000 شیء را طبقه بندی کند. اندازه ورودی تصویر این شبکه 299x299 پیکسل بود که بزرگتر از شبکه VGG19 است. در حالی که VGG19 در مسابقات ImageNet 2014 نایب قهرمان بود ، Inception برنده بود. خلاصه مختصری از ویژگی های Inceptionv3 به شرح زیر است:
 شکل 5. تصویری از شبکه Inceptionv3 (تصویر مسعود مهدیانپری ، بهرام صالحی و محمد رضایی در ResearchGate)
شکل 5. تصویری از شبکه Inceptionv3 (تصویر مسعود مهدیانپری ، بهرام صالحی و محمد رضایی در ResearchGate) ResNet50 (شبکه باقیمانده)
ResNet50 یک شبکه عصبی پیچشی است که عمق آن 50 لایه است. در سال 2015 توسط مایکروسافت ساخته و آموزش داده شد و می توانید به نتایج عملکرد مدل در مقاله آنها با عنوان یادگیری عمیق باقی مانده برای تشخیص تصویر دسترسی پیدا کنید. این مدل همچنین بر روی بیش از 1 میلیون تصویر از پایگاه داده ImageNet آموزش دیده است. درست مانند VGG-19 ، می تواند تا 1000 شی را طبقه بندی کند و شبکه بر روی تصاویر رنگی 224x224 پیکسل آموزش دیده است. در اینجا اطلاعات مختصری در مورد اندازه و عملکرد آن وجود دارد:
اگر ResNet50 را با VGG19 مقایسه کنید ، خواهید دید که ResNet50 در واقع از VGG19 بهتر است حتی اگر پیچیدگی کمتری دارد. ResNet50 چندین بار بهبود یافته است و همچنین به نسخه های جدیدتری مانند ResNet101 ، ResNet152 ، ResNet50V2 ، ResNet101V2 ، ResNet152V2 دسترسی دارید.
 شکل 6. تصویری از شبکه ResNet50 (تصویر مسعود مهدیانپری ، بهرام صالحی و محمد رضایی در ResearchGate)
شکل 6. تصویری از شبکه ResNet50 (تصویر مسعود مهدیانپری ، بهرام صالحی و محمد رضایی در ResearchGate) EfficientNet
EfficientNet is یک شبکه عصبی پیچیده پیشرفته که توسط Google با مقاله "EfficientNet: بازاندیشی مدل مقیاس بندی برای شبکه های عصبی کانولوشن" در سال 2019 آموزش داده و برای عموم منتشر شد. 8 پیاده سازی جایگزین EfficientNet (B0 تا B7) وجود دارد و حتی ساده ترین آن ، EfficientNetB0 ، برجسته است. با 5.3 میلیون پارامتر ، عملکرد 77.1٪ Top-1 را انجام می دهد.
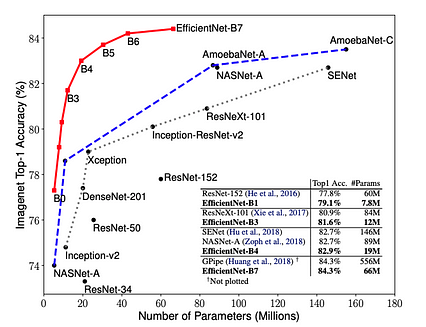 شکل 7. اندازه مدل EfficientNet در مقابل دقت ImageNet (طرح Mingxing Tan و Quoc V. Le در Arxiv)
شکل 7. اندازه مدل EfficientNet در مقابل دقت ImageNet (طرح Mingxing Tan و Quoc V. Le در Arxiv) خلاصه مختصری از ویژگی های EfficientNetB0 به شرح زیر است:
سایر مدلهای از پیش آموزش دیده برای مشکلات بینایی رایانه
ما چهار مورد را ذکر کردیممدل های شبکه عصبی پیچیده ای که برنده جایزه شده است. با این حال ، ده ها مدل دیگر برای آموزش انتقال وجود دارد. در اینجا یک تجزیه و تحلیل معیار از این مدل ها وجود دارد که همه آنها در برنامه های Keras موجود هستند.
نتیجه گیری
در دنیایی که ما به راحتی به شبکه عصبی پیشرفته دسترسی داریم مدل ها ، تلاش برای ساختن مدل خود با منابع محدود مانند تلاش برای اختراع مجدد چرخ است. بی فایده است.
در عوض سعی کنید با این مدل های قطار کار کنید ، چند لایه جدید با توجه به وظیفه بینایی رایانه ای خاص خود اضافه کنید و تمرین کنید. نتایج بسیار موفقیت آمیزتر از مدلی خواهد بود که از ابتدا ایجاد کرده اید.
برای دریافت کد کامل در فهرست نامه عضویت
اگر می خواهید به کد کامل در Google دسترسی داشته باشید Colab و دسترسی به آخرین مطالب من ، عضویت در لیست پستی: ✉️
از مقاله لذت بردید؟
اگر این مقاله را دوست دارید ، در نظر بگیرید بررسی سایر مقالات مشابه من:
نحوه حذف همه پوشه های Node_Modules در رایانه
نحوه حذف همه پوشه های Node_Modules در رایانه
استفاده از npkill برای پاکسازی فضای دیسک
 عکس توسط توماس پارک در Unsplash
عکس توسط توماس پارک در Unsplash به عنوان توسعه دهندگان Frontend ، از npm برای مدیریت وابستگی های dev و زمان اجرا استفاده می کنیم. وقتی npm install یا yarn install را اجرا می کنیم ، صدها مگابایت وابستگی را بارگیری می کنیم و آنها را در فهرست پروژه node_modules ذخیره می کنیم. برای یک برنامه کوچک React ، وقتی همه وابستگی های dev خود را در نظر بگیرید و وابستگی های زمان را اجرا کنید ، این می تواند به سرعت افزایش یابد.
لپ تاپ شخصی من یک مک بوک با هارد دیسک 128 گیگ است. بین پروژه های جانبی ، برنامه های کوچکی که برای آزمایش کتابخانه ها ایجاد می کنم و عکس ها ، این کار فضای بیشتری روی رایانه من نمی گذارد. هر چند هفته یکبار متوجه می شوم که کامپیوترم کندتر و کندتر کار می کند. این به دلیل اشغال فضای زیادی از هارد دیسک من توسط node_modules است. در حالی که می توانستم در تمام پروژه های موجود در پوشه dev خود حرکت کنم و پوشه های node_modules را به صورت دستی حذف کنم ، این کار زمان می برد.
خوشبختانه ، راه بهتری وجود دارد. بسته npkill هر پوشه node_modules در سیستم شما و همچنین میزان فضایی که آنها اشغال می کنند را لیست می کند. سپس می توانید پوشه های node_modules را حذف کنید.
برای شروع ، برنامه را با دستور npx زیر اجرا کنید.
npx npkill
به طور پیش فرض ، npkill جستجویی از دایرکتوری ای که در حال حاضر در آن هستید. برای نادیده گرفتن این مورد ، می توانید از استدلال - /cdn-images-1.medium.com/max/426/1*JaFS4Qby7mUhfhRYkxMoIQ.jpeg">
همانطور که در تصویر مشاهده می کنید ، npkill همه پوشه های node_modules ما را به ما نشان می دهد و به ما امکان حذف را می دهد آنها را یکی یکی با ضربه زدن به نوار فاصله. یکی دیگر از راههای عالی برای پاکسازی فضای دستگاه این است که همه پوشه های dist خود را حذف کنید. برای انجام این کار با npkill ، به سادگی از استدلال --target
npx npkill -Target dist
برای کسب اطلاعات بیشتر در مورد استدلال های مختلفی که npkill می پذیرد ، از مخزن github آنها دیدن کنید.
مجدداً از اینکه وقت خود را برای مطالعه این مقاله اختصاص دادید و برای حمایت از Frontend Digest ادامه دادید متشکریم.
ما همیشه به دنبال نویسندگان جدید هستیم ، اگر علاقه مند به نوشتن برای ما هستید ، اجازه دهید ما می دانیم!
من فقط یک کامپیوتر جدید خریدم تا CUDA را امتحان کنم ، آیا ارزشش را داشت؟
من فقط یک کامپیوتر جدید خریدم تا CUDA را امتحان کنم ، آیا ارزشش را داشت؟

امکان پردازش گرافیکی برای محاسبات آماری همیشه مورد توجه من بوده است. من اخیراً از بسته های OpenCL زیادی استفاده می کنم تا بسته های مبتنی بر CPU ، زیرا کارت گرافیک من توسط AMD تولید می شود و OpenCL تنها مشارکت کافی آنها در برنامه نویسان است که می خواهند از قدرت استفاده کنند. GPU برای ریاضیات ، نه فقط گرافیک.
مطمئناً در لیست چیزهایی که به نظرم جذاب است CUDA است ، که یک پلت فرم محاسباتی موازی اختصاصی Nvidia است. با این حال ، آخرین پردازنده گرافیکی Nvidia که من در اختیار داشتم 8800GT بود و همه کارت هایی که دور آن نشسته ام قرمز رنگ هستند ، بیشتر آنها کارت های قدیمی تر هستند (من سخت افزار سخت افزاری هستم.)
بنابراین برای در دو هفته گذشته ، من چند بار جستجو نکرده بودم ، اما Letgo ، Facebook و Craigslist را برای سخت افزاری که به آن علاقه داشتم ، یک بار بررسی کردم:
و در آخرین هوس جستجوی خود ، با یک کشف تکان دهنده برخورد کردم.

این رایانه در Letgo با قیمتی بسیار ناچیز 140 دلار وارد بازار شد ، اما چند نگرانی وجود داشت. بدیهی است که من می خواهم پردازنده را بشناسم ، اما می توانم بگویم سوکت AM3+ بود که خبر خوبی بود ، و هر پردازنده ای که در آنجا بود باید با خنک کننده با رادیاتور عظیم 240 میلی متری که در جلوی قاب نصب شده بود ، ارزش خنک شدن داشته باشد.
علاوه بر این ، کارت گرافیک یک یاقوت کبود با یک PCB آبی است ، PCB آبی مهم است زیرا Sapphire دیگر از آنها استفاده نمی کند ، حداقل تا آنجا که من می دانم ، و آنها معمولاً با سری Radeon HD مرتبط هستند به بدیهی است که Radeon HD برای CUDA هیچ تفاوتی ندارد و تا آنجا که می توانید از کارت Nvidia دریافت کنید. 140 دلار! انگشتانم را روی هم می گذراندم به این امید که این برد دارای پردازنده هشت هسته ای AMD FX یا چیزی شبیه به آن (piledriver ، نه بولدوزر) باشد. نتیجه یک هشت هسته AMD FX 830e با فرکانس 3.5 گیگاهرتز بود.
اما هنوز ؛ کارت گرافیک به مردی که رایانه می فروشد پیام داد تا چند س questionsال بپرسد و از او خواستم در بایوس بایستد تا برخی از مشخصات من را بررسی کند. این سیستم تا 8 گیگابایت رم در دو کاناله ، منبع تغذیه ماژولار 750 وات ، رادیاتور 240 میلی متری/AIO ، SSD 128 گیگابایتی (از سرعت خواندن و نوشتن مطمئن نیست) ، مقداری مادربرد Aura و این کارت Saphire اضافه کرده است.
اما برای این که معامله شیرین تر شود ، او فاش کرد که علاوه بر مشخصاتی که به من می فروخت ، با بیست دلار اضافی ، یک کارت گرافیک GTX 1060 ROG strix strix را با آن به من می فروخت!
پس از بردن آن به خانه ، همه را جمع کردم ، SSD را با سیستم عامل روی آن (POP! Os) عوض کردم ، به EFI بوت کردم و همه چیز کاملاً کار کرد. من برخی از ارتقاء ها را اضافه کردم ، SSD 570 Evo ،هشت گیگابایت حافظه اضافی و R9 290 برای هدایت هرگونه نمایشگر اضافی ، برای نتیجه ای که کمی شبیه این است:

در حال حاضر که سخت افزار را به سمت پایین داریم ، باید همین کار را برای نرم افزار انجام دهیم!
< h1> کارکردن CUDAراه اندازی CUDA در واقع بسیار گسترده است ، زیرا به سادگی تنظیم درایورها ساده نیست. در مرحله اول ، باید وارد پایانه خود شوید و وابستگی ها را نصب کنید:
sudo apt-get install freeglut3 freeglut3-dev libxi-dev libxmu-dev
سپس باید به "Cuda Zone" و چند فایل دوتایی برای خود بگیرید ... یا اگر در دبیان هستید ، می توانید repo را انتخاب کنید:
wget http://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run
و سپس فایل sh را از repo (به عنوان ریشه) اجرا می کنیم:
sudo sh ./cuda_10.1.243_418 .87.00_linux.run
همچنین راهی برای نصب محیط CUDA با DPKG وجود دارد ، اما من نسخه SH را انتخاب کردم ، زیرا این مسیر معمولاً مسیر مورد علاقه من با منابع قابل اعتماد مانند Nvidia است. وقتی از طریق SH نصب می کنید ، چند س questionsال از شما پرسیده می شود ، من # نظر در مورد پاسخ هایم توضیح دادم تا بتوانید تصمیم بگیرید که آیا بله گفتن را مناسب می دانید یا خیر.
در حال تلاش برای نصب بر روی پیکربندی پشتیبانی نشده هستید به آیا می خواهید ادامه دهید؟ (y) es/(n) o [پیش فرض هیچ]: y
# بدیهی است ، ما باید این کار را برای ادامه نصب CUDA انجام دهیم.
NVIDIA Accelerated Graphics Driver را برای Linux-x86_64 396.26 نصب کنید؟ (y) es/(n) o/(q) uit: n
# من به این مورد نه گفتم ، زیرا از POP استفاده می کنم! OS Nvida Driver
جعبه ابزار CUDA 9.2 را نصب کنید؟ (y) es/(n) o/(q) uit: y
# البته تمام دلیلی که ما اینجا هستیم مربوط به جعبه ابزار
وارد کردن مکان جعبه ابزار است [به طور پیش فرض /usr/local/cuda-9.2] است:
# آن مکان برای من مناسب بود.
آیا می خواهید یک پیوند نمادین در/usr/local/cuda نصب کنید؟ (y) es/(n) o/(q) uit: y
# دلیلی برای عدم وجود ندارد ، بنابراین جهانی است و با همه چیز قابل استفاده است.
نمونه های CUDA 9.2 را نصب کنید ؟ (y) es/(n) o/(q) uit: y
# من فهمیدم چرا نه ، بنابراین می توانم کاربرد آن را در Python و C را ببینم ، زیرا بسیاری از نوشته ها را در آنجا انجام می دهم. .
محل نمونه CUDA را وارد کنید [به طور پیش فرض/home/kinghorn]: /usr/local/cuda-9.2
نصب وصله cuBLAS:
sudo sh cuda_9.2.88.1_linux.run
آخرین و مهمترین نکته این است که ما باید مسیرهای echo را به سیستم خود اضافه کنیم ، این کار را ابتدا با ایجاد یک فایل sh در آدرس:
/etc/profile.d/cuda.sh
و قرار دادن موارد زیر در آن:
export PATH = $ PATH:/usr/local/cuda/bin CUDADIR =/usr/local/cuda
و فایل sh دیگر در:
/etc/ld.so.conf.d/cuda.conf
شامل:
/usr/local/cuda/lib64
البته ، ما باید این موارد را به عنوان یک استفاده کننده فوق العاده ویرایش کنیم. و سپس در نهایت می توانیم
sudo ldconfig
در حال حاضر راه اندازی CUDA را اجرا کنیم! هیجان من به طرز چشمگیری افزایش می یابد! حالا بیایید وارد جولیا شویم و بسته های خود را تنظیم کنیم! این باید بسیار آسان باشد ، اما در اینجا خواهیم فهمید که آیا POP! درایورها سازگار خواهند بود ما به بسته های زیر نیاز داریم:
CuArrays CUDAnative CUDAdrv
و سپس برای اطمینان از کارکردن همه چیز ، این مسیرها را پیش می برم و سپس هر بسته را می سازم:
ENV ["LD_LIBRARY_PATH"] = "/usr/lib/cuda/lib64 "
ENV ["CUDA_PATH"] = "/usr/lib/cuda"
استفاده از Pkg ؛ Pkg.build ("CuArrays")
Pkg.build ("CUDAnative")
Pkg.build ("CUDAdrv") فقط برای روشن کردن Jupyter و آزمایش آن!
ERROR: LoadError: زنجیره ابزار موجود CUDA libcudadevrt
کمک کنید ، این مایه تاسف است. به نظر می رسد که مجبور باشیم درایورهای انویدیا را نصب کنیم ، من واقعاً امیدوار بودم که درایورهای POP ممکن است درایورها را کار کنند ، اما به نظر نمی رسد که چنین باشد ، یا اگر باشد ، کمی بیش از حد تغییر کرده است.
سرانجام کار می کند
پس از کمی اصلاحدر کنترل پنل CUDA ، و برخی از ویرایش های bashrc از طرف من ، سرانجام درایورهای CUDA من کار می کردند. بنابراین چگونه زمان بین جولیا در CPU و عملکرد رگرسیون خطی مجدد در CPU من مقایسه شد؟ من آنچه را که ما دانشمندان داده بهتر انجام می دهیم انجام دادم و بیست بار آزمایش را انجام دادم و میانگین هر دو ویژگی را بدست آوردم:
0.2208722 ثانیه
0.052839374 ثانیه
با چنین افزایشی ، تصمیم گرفتم سومین آزمایش جداگانه را تنها با OpenCL انجام دهم ، و نتایج حیرت انگیز بودند:
0.10083948593 ثانیه
نتیجه گیری
دستاوردهای قابل توجه در عملکرد برای یادگیری عمیق ، و مدل سازی ساده پیش بینی ، هنگام استفاده از CUDA قطعاً وجود داشت. در آینده ، من می خواهم از یک کارت با هسته Tensor نیز استفاده کنم ، زیرا مطمئناً سرعت آن بی عیب و نقص خواهد بود. صرف نظر از این ، من از این که همه اینها چگونه پیش رفت بسیار خوشحالم! بنابراین آیا خرید یک دستگاه کاملاً جدید برای استفاده از CUDA ارزشش را داشت؟
سنسورهای عمق کلید باز کردن قفل برنامه های بینایی کامپیوتر در سطح بعدی هستند.
سنسورهای عمق کلید باز کردن قفل برنامه های بینایی کامپیوتر در سطح بعدی هستند.
این راهنمای سنسورهای عمق ، اولین مورد از بسیاری از آزمایشگاه های Comet برای نوآوری های عمیق فناوری در هوش مصنوعی و روباتیک است.
< p> ایجاد شده توسط رولاند لیشاید چند داستان در مورد آیفون 8 آینده مشاهده کرده باشید. از جمله موارد مهم دیگر ، انتظار می رود که iPhone 8 دارای قابلیت های AR بسیار بهتری باشد (پشتیبانی از کیت AR انتشار) و همچنین یک سنسور لیزری با دوربین دوگانه آن.
اما چرا باید به این دوربین جدید و ترکیب لیزری اهمیت دهید؟ زیرا آنها اجزای ضروری برای تشخیص عمق هستند که نحوه تعامل مردم در آینده نزدیک را کاملاً تغییر می دهد.
در اصل ، یک دوربین معمولی دنیای سه بعدی را به یک تصویر دو بعدی تبدیل می کند. تا کنون ، تصاویر دو بعدی به اندازه کافی برای مصرف کنندگان خوب در نظر گرفته می شد و بعد سوم از دست رفته در تصویربرداری دو بعدی بی اهمیت به نظر می رسید.
اما همه چیز تغییر کرده است. با پیشرفت سرسام آور بینایی رایانه ای (CV) همراه با یادگیری عمیق ، بسیاری از محققان بلندپرواز سعی کرده اند ماشین ها را از طریق یک دوربین به دنیای ما بفهمانند تا بتوانند با انجام بسیاری از وظایف ، توانایی های انسان را افزایش دهند. در حال حاضر ، CV می تواند با موفقیت کارهایی مانند تشخیص دست خط ، طبقه بندی اشیاء را انجام دهد و جزء مهمی برای فعال کردن وسایل نقلیه خودران است. در بسیاری از وظایفی که اطلاعات دو بعدی کافی است ، الگوریتم های CV وعده های زیادی را نشان داده اند. با این حال ، وقتی با دنیای واقعی سه بعدی سروکار دارند ، محققان متوجه می شوند که یک تنگنای CV وجود دارد. انسان دو چشم دارد که به ما امکان می دهد عمق را به طور طبیعی حس کنیم. با این حال ، اکثر برنامه های CV برای ضبط و تفسیر جهان اطراف به یک دوربین وابسته هستند. بعد سوم از دست رفته به طور قابل توجهی عملکرد CV را محدود می کند.

در شکل بالا ، الگوریتم CV در پاسخ دادن به این س questionsالات مشکل خواهد داشت ، اما انسانها می توانند به راحتی این کار را انجام دهند. از آنجایی که سناریوی دنیای واقعی از سه بعدی به دو بعدی پیش بینی شده بود ، این دو س suddenlyال ناگهان بی اهمیت می شوند.
عمق اطلاعات مهمی را حمل می کند. به عنوان مثال ، اگر توپ های قرمز و سیاه به جای وسایل نقلیه در جاده بودند ، ما می خواهیم یک الگوریتم رزومه (CV) بفهمد که کدام یک نزدیکتر است تا نمایشی دقیق از وضعیت به دست آورد. متأسفانه ، ما نمی توانیم به الگوریتم های CV مبتنی بر 2D تکیه کنیم. ما برای ضبط اطلاعات کامل دنیای واقعی خود به سنجش عمق به همراه تصویربرداری دو بعدی نیاز داریم.
راهنمای زیر به شما کمک می کند تا بفهمید که حسگر عمق در حال حاضر چگونه کار می کند و در کجا از آن استفاده می شود.
جستجوی سریع: کاربردهای حساسیت عمق و هوش مصنوعی
1. AR /VR: برای تشخیص محیطهای سه بعدی واقعی و بازسازی آنها در دنیای مجازی < /h4>
به عنوان مثال ، پروژه تانگو توسط Google از سنسورهای عمق برای اندازه گیری دقیق محیط واقعی و اطلاع از الگوریتم های گرافیکی خود برای قرار دادن محتوای مجازی در مکان مناسب استفاده می کند. موقعیت ها در مقایسه با حالت AR Pokemon Go ، جایی که کاربران اغلب می توانند Pokemon را در موقعیت های نادرست قرار دهند زیرا الگوریتم اطلاعات عمق محیط را ندارد.
اطلاعات عمق نیز برای تعامل انسان و ماشین VR/AR ضروری است. دستگاه ها دستگاهها باید به حرکت سه بعدی کاربران دقیق پاسخ دهند ،که قطعاً به سنسورهای عمق با عملکرد بالا نیاز دارند.
2. روباتیک: برای ناوبری ، محلی سازی ، نقشه برداری و جلوگیری از برخورد
بسیاری از انبارها در حال حاضر از وسایل نقلیه کاملاً خودمختار استفاده می کنند که اشیاء را از مکانی به مکان دیگر منتقل می کنند. توانایی حرکت وسیله نقلیه به تنهایی مستلزم تشخیص عمق است تا بتواند بداند کجا در محیط است ، سایر موارد مهم کجاست و از همه مهمتر چگونه می تواند با خیال راحت از A به B برسد. به طور مشابه ، هر رباتی که برای اهداف انتخابی بستگی به تشخیص عمق دارد تا بداند شیء مورد نظر کجاست و چگونه باید آن را بدست آورد. در واقع ، یکی از مهمترین چالش های خودروهای خودران در حال حاضر تجهیز خودرو به سنسور عمق دقیق و سیستم CV بدون افزایش هزینه به میزان چشمگیر است. این هنوز بازار رقابتی است که در آن بسیاری از استارتاپ های جدید برای رهبری رقابت می کنند.
3. تشخیص چهره: برای بهبود راحتی و جلوگیری از کلاهبرداری
اکثر سیستم های تشخیص چهره از دوربین دو بعدی برای ثبت عکس و ارسال آن به الگوریتم برای تعیین هویت شخص استفاده می کنند. با این حال ، این یک خلأ قابل توجه است: یک بازیگر بد می تواند سیستم ها را فریب دهد زیرا نمی توانند تشخیص دهند که در حال مشاهده یک چهره سه بعدی واقعی است یا یک عکس دو بعدی. برای ایمن سازی تشخیص چهره ، دوربین های سه بعدی با تشخیص عمق ضروری هستند.
 < /img>
< /img> علاوه بر مسدود کردن این روزنه ، مدل سازی چهره سه بعدی همچنین ویژگی های بیشتری از چهره را برای تشخیص دقیق تر ارتباط می دهد. طبق شایعات ، آیفون 8 آینده دارای سنسور عمق به منظور تشخیص چهره است و انتظار می رود شرکت های بیشتری از اپل در تشخیص عمق در دستگاه های خود نیز پیروی کنند.
4. تشخیص ژست و مجاورت: برای بازی ، امنیت و سایر موارد.
سنسورهای عمق Time-of-Flight (ToF) در حال حاضر توسط بسیاری از دستگاهها برای این منظور استفاده می شود. در پیاده سازی های ساده ، یک سنسور عمق فقط باید اطلاعات عمق یک نقطه را تشخیص دهد ، مانند دستی برای تشخیص حرکت یا چهره ای برای تشخیص مجاورت. بنابراین یک سیستم سنجش عمق با نوری ساده (و یک میدان دید باریک) کافی است. با تکامل تشخیص حرکت ، از سیستم های تشخیص عمق پیچیده تر ، مانند Kinect مایکروسافت ، استفاده می شود. به درست مانند زمانی که از پنجره می بینید ، کل تصویر را به آسمان ، ماشین ها ، ساختمانها و هر چیز دیگری که در میدان دید شما قرار دارد تقسیم می کنید.
این نیز کلید تجزیه و تحلیل تصویر است: با تقسیم بندی ضعیف ، عملکرد کارهای بعدی نیز تنزل یافته است. طبیعی است که انسان بدون آموزش زیاد بخش بندی کند زیرا ما دو چشم داریم و می توانیم از نمای سه بعدی استفاده کنیم. رزومه معمولی فقط یک دوربین RGB دارد ، بنابراین تقسیم بندی عمدتا بر اساس مدل سازی آماری است. در حال حاضر ، یادگیری عمیق به سختی می تواند با به خاطر سپردن سرنخ های کلیدی معمولی ، مانند تغییر رنگ ، لبه ، بافت و غیره تقسیم بندی شود.
با این حال ، این روش تقسیم بندی مبتنی بر یادگیری به طور کامل از اطلاعات در دنیای سه بعدی استفاده نمی کند ، بنابراین دقیق نیست همچنین ، بازده محاسباتی آن بسیار ضعیف است. تصویر مبتنی بر یادگیری عمیقتجزیه و تحلیل معمولاً مقدار زیادی انرژی مصرف می کند که مقیاس بندی این روش را دشوار می کند. به عنوان مثال ، یک پردازنده گرافیکی اختصاصی تلفن همراه از Nvidia (TX1) تنها می تواند کمتر از 10 فریم در ثانیه با مصرف برق 10 وات اجرا کند. کارت گرافیک Nvidia Titan X یک پردازنده گرافیکی پیشرفته برای سمت سرور است و می تواند بسیار سریعتر در حدود 40-50 فریم بر ثانیه اجرا شود ، اما به 250 وات نیرو نیاز دارد و برای برنامه های تلفن همراه نامناسب است. علاوه بر این ، این پردازنده های گرافیکی بسیار گران هستند و از 300 دلار تا 1000 دلار متغیر هستند.
اگر ما یک کامپیوتر با اطلاعات سه بعدی جهان خود ارائه دهیم ، CV می تواند در تقسیم بندی معنایی با مصرف انرژی کمتر کار بسیار بهتری انجام دهد. ما به یک شبکه عصبی پیچیده احتیاج نداریم ، زیرا یک الگوریتم اصلی توسعه منطقه یا حتی یک الگوریتم خوشه بندی می تواند کار شایسته ای انجام دهد. با آن الگوریتم های کم هزینه ، بار محاسباتی در مقایسه با CNN (یا سایر الگوریتم های CV معمولی مبتنی بر 2D) اساساً ناچیز است (از نظر تعداد عملیات و پهنای باند حافظه) و یک SoC موبایل با مصرف انرژی بالا می تواند کار را در زمان واقعی به پایان برساند. .
پیشرفته ترین دوربین های سه بعدی ، مانند دوربین Kinect2 ، کمتر از 5 وات مصرف می کنند و می توانند با سرعت مناسب 30 فریم در ثانیه اجرا شوند. همراه با مصرف برق SoC تلفن همراه (W 2W) ، این عملکرد با TitanX قابل مقایسه است اما با 30X صرفه جویی در انرژی. هزینه سنسور سه بعدی نیز بسیار کمتر از GPU است (در حجم زیاد کمتر از $ 10). بنابراین ، سنجش عمق می تواند یک عامل کلیدی برای برنامه های کاربردی تصویر و موبایل هوشمند در آینده باشد ، جایی که بودجه انرژی بسیار محدود است.

با افزایش تقسیم بندی ، تشخیص شی با استفاده از دوربین سه بعدی نتایج بهتری را به ارمغان می آورد. همانطور که توسط محققان دانشگاه برکلی در مقاله ای تحت عنوان "یادگیری ویژگی های غنی از تصاویر RGB-D برای تشخیص و تقسیم بندی اجسام" گزارش شده است ، پیشرفت قابل توجهی مشاهده شد: با پیشرفته ترین فناوری 2 بعدی R-CNN ، میانگین متوسط دقت در مقایسه با یک شبکه عصبی عمیق RGB-D با متوسط متوسط 37.5 درصد ، 22.5 درصد بود. یادگیری عمیق با RGB-D محققان زیادی را به خود جلب کرده است و چندین موسسه (مانند دانشگاه واشنگتن و NYU) حتی مجموعه داده های در مقیاس متوسط برای RGB-D را که همتای ImageNet در جهان RGB هستند منتشر کرده اند. ما انتظار داریم در آینده نزدیک شاهد آثار بیشتری باشیم که RGB-D را با یادگیری عمیق ترکیب می کند.
در حال حاضر تنگنای اصلی الگوریتم های CV مبتنی بر حس سه بعدی هنوز مجموعه داده است. اگرچه افزایش داده ها و سایر تکنیک ها می توانند به آموزش یک شبکه عصبی مناسب برای اطلاعات سه بعدی بدون حجم عظیمی از داده ها کمک کنند ، در نهایت ما به یک مجموعه داده بزرگ (مانند ImageNet و Microsoft COCO در جهان دو بعدی) برای آموزش و محک زدن یک شبکه عصبی کاملاً بهینه نیاز داریم. < /p>
مروری بر روشهای تشخیص عمق
نور ساختاری:
با استفاده از منبع نور لیزری برای نمایش الگوی شناخته شده ، گیرنده اعوجاج الگوی منعکس شده را تشخیص می دهد محاسبه نقشه عمق بر اساس هندسه برای بدست آوردن نقشه عمق که زمان می برد ، باید تمام سطح را اسکن کند ، اما بسیار دقیق است. با این حال ، این روش به روشنایی محیط حساس است ، بنابراین معمولاً فقط در مناطق تاریک یا داخلی اجرا می شود.
زمان پرواز (ToF):
دو رویکرد اصلی وجود دارد. اولینساده است: یک منبع لیزری یک پالس را ارسال می کند و یک سنسور بازتاب آن پالس را از شیء هدف تشخیص می دهد تا زمان پرواز را ثبت کند. با آگاهی از آن و سرعت ثابت نور ، سیستم می تواند محاسبه کند که جسم مورد نظر چقدر دور است. برای اطمینان از دقت بالا ، دوره پالس باید کوتاه باشد ، که منجر به هزینه بیشتری می شود. همچنین ، یک مبدل زمان به دیجیتال با وضوح بالا مورد نیاز است که می تواند برق زیادی مصرف کند. این رویکرد را عموماً می توان در سنسورهای ToF با کارایی بالا یافت.
یکی دیگر از روش های محاسبه زمان ، ارسال یک منبع نور تعدیل شده و تشخیص تغییر فاز نور منعکس شده است. تغییر فاز را می توان به آسانی با تکنیک اختلاط اندازه گیری کرد. تعدیل منبع لیزر آسان تر از ارسال پالس های کوتاه است و اجرای تکنیک مخلوط کردن ساده تر از مبدل زمان به دیجیتال است. همچنین ، LED می تواند به عنوان منبع نور تعدیل شده جایگزین لیزر شود. بنابراین سیستم ToF مبتنی بر مدولاسیون برای سنسورهای ارزان قیمت ToF مناسب است. هدف ، و نقشه عمق بر اساس هندسه محاسبه می شود. این حالت در دید رایانه ای "stereoview" یا "stereoscopic" نیز نامیده می شود. ساده ترین و در عین حال محبوب ترین آرایه دوربین ، دوربین دوگانه است ، جایی که دو دوربین با فاصله از یکدیگر برای تقلید از چشم انسان از هم جدا شده اند. برای هر نقطه در فضا ، با اختلاف قابل اندازه گیری موقعیت ها در دو تصویر دوربین ظاهر می شود. سپس عمق با هندسه اصلی محاسبه می شود.

اصلی چالش آرایه دوربین نحوه یافتن نقاط مطابقت در چندین تصویر است. جستجوی نقطه تطبیق شامل الگوریتم CV پیچیده است. در حال حاضر یادگیری عمیق می تواند به یافتن نقاط مطابقت با دقت خوب کمک کند ، اما هزینه محاسبه آن زیاد است. علاوه بر این ، نقاط زیادی وجود دارد که یافتن نقاط منطبق بر آنها دشوار است. به عنوان مثال ، در دو نمای مجسمه واگنر در بالا ، بینی ساده ترین نقطه برای تطبیق است زیرا ویژگی های آن به راحتی قابل استخراج و مقایسه هستند. با این حال ، برای سایر قسمتهای صورت (به ویژه سطح صورت بدون بافت) ، پیدا کردن نقاط منطبق بسیار دشوار است. وقتی انسداد برای دو تصویر دوربین متفاوت باشد ، تطبیق حتی پیچیده تر است. در حال حاضر ، استحکام آرایه دوربین به عنوان سنسور عمق هنوز یک مشکل چالش برانگیز است.
مقایسه روش ها
عملکرد کلی
برای تشخیص عمق ، مهمترین معیار دقت عمق است نور ساختاری بهترین عملکرد عمق را دارد ، در حالی که آرایه دوربین بیشترین خطای عمق را دارد.
از نظر محدوده تشخیص عمق ، نور ساختاری کوتاهترین برد را دارد ، در حالی که محدوده ToF بستگی به قدرت تابش دارد از منبع نور به عنوان مثال ، دستگاه های هوشمند ممکن است تنها به برد چند متر نیاز داشته باشند ، در حالی که چند صد متر برای خودروهای خودران مورد نیاز است. به طور مشابه ، محدوده اندازه گیری آرایه دوربین بستگی به فضای بین دو دوربین دارد. برای یک آرایه معمولی دوربین ، بهترین محدوده اندازه گیری عملکرد معمولاً در حدود 10 متر است ، اگرچه آرایه های دوربین خاصی با فضای بسیار باریک نیز عمق را در حدود 1 متر اندازه گیری کرده اند.
برایوضوح نقشه عمق ، نور ساختاری بهتر از ToF عمل می کند ، زیرا الگوی ساطع کننده نور ساختاری را می توان به طور دقیق کنترل کرد و الگوی بازتاب شده آن را به طور دقیق ضبط کرد. از لحاظ نظری ، یک آرایه دوربین وضوح خوبی دارد ، با این حال این بر اساس یک نقطه کامل مطابقت در دو تصویر است. با تطبیق نقطه ای غیر ایده آل (مانند سطوح صاف) ، وضوح کاهش می یابد.
در نهایت ، ما باید محدودیت هایی را برای روشنایی محیط در نظر بگیریم. نور ساختاری به محیط تاریک احتیاج دارد ، در حالی که حسگرهای ToF می توانند طیف وسیع تری از روشنایی محیط را به لطف پیشرفت سریع فناوری های لغو پس زمینه تحمل کنند. برای یک آرایه دوربین ، یک محیط روشن بهترین کار را می کند. وقتی در یک اتاق تاریک ، تصاویر گرفته شده توسط یک آرایه دوربین پر سر و صدا می شوند و کنتراست ضعیف می شود ، بنابراین تطبیق نقطه بسیار دشوار می شود و در نتیجه تخمین عمق نادرست انجام می شود.
هزینه
هزینه آرایه دوربین معمولاً پایین ترین است و تلاش توسعه آن عمدتا در سمت نرم افزار است. راه حل دوربین دوگانه قبلاً به طور گسترده در بسیاری از دستگاه های هوشمند و تلفن های همراه استفاده شده است. سنسور ToF هزینه متوسطی دارد ، در حالی که نور ساختاری بیشترین هزینه را دارد. با این حال ، با تولید انبوه ToF ، انتظار می رود هزینه آن در آینده نزدیک به میزان قابل توجهی کاهش یابد. می تواند به بهترین نحو برای نیازهای آینده ما تکیه کند. ToF فناوری نیمه هادی است و بهترین مقیاس پذیری را دارد. دقت عمق آن را می توان با مدار مبدل/مخلوط زمان به دیجیتال روی تراشه ، وضوح نقشه عمق آن را با اندازه سنسور ، مقیاس اندازه گیری آن را می توان با منبع قدرت/طرح مدولاسیون نور ، و مصرف برق آن را افزایش داد. با فناوری نیمه هادی مقیاس پذیر شود.
از طرف دیگر ، نور ساختاری مقیاس پذیری مناسبی دارد. سیستم نوری یک جزء کلیدی در نور ساختاری است و سیستم نوری می تواند با فناوری بسته بندی (هر چند نه به اندازه نیمه هادی) مقیاس پذیری داشته باشد.
در نهایت ، مقیاس بندی یک آرایه دوربین عمدتا به نرم افزار بستگی دارد: ما به الگوریتم های بهتری نیاز داریم مقیاس عملکرد سنجش عمق آن. این بیشتر شبیه یک مشکل ریاضی است و نه یک مشکل مهندسی ، و بهبود سخت افزار کمک چندانی نخواهد کرد. حتی در دوربین های با وضوح بسیار بالاتر ، مشکل تطبیق نقطه همچنان وجود دارد.

 منبع: Texas Instruments
منبع: Texas Instruments فقط نور ساختاری برای انجام کارهای بیومتریک توصیه می شود زیرا دارای بهترین دقت عمق است. برنامه های بازی نیاز به وضوح متوسط عمیق و پاسخ سریع دارند ، بنابراین به نظر می رسد سنسور ToF بهترین گزینه است. برای سایر برنامه ها از جمله مکان ، شناسایی ، اندازه گیری و AR ، همه فناوری ها می توانند آنها را انجام دهند ، اما برخی از آنها برای سناریوهای کاربردی خاص بهتر از سایرین هستند. به عنوان مثال ، یک آرایه دوربین احتمالاً برای برنامه های AR در فضای باز که اندازه گیری عمق نیاز به محدوده اندازه گیری زیادی دارد ، بهترین است ، در حالی که سنسور ToF برای AR داخلی ، جایی که می توان روشنایی محیط را کنترل کرد ، بهترین است.
System Teardown < /h1> نور ساختاری:
یک سیستم نور ساختاری معمولی شامل پروژکتور و دوربین است. پروژکتور نور را بر روی یک شیء قرار می دهد و دوربین نور منعکس شده را ضبط می کند.

پروژکتور دارای دو قسمت است: منبع لیزر و ژنراتور الگو. منبع لیزر به طور کلی از VCSEL یا دیود لیزری لبه ای استفاده می کند که با فناوری نیمه هادی برای تولید لیزر مادون قرمز استفاده می شود. سنجش عمقاین یک فرصت بزرگ برای صنعت لیزر است ، و در نتیجه بسیاری از تولید کنندگان قطعات لیزر سرمایه گذاری زیادی در برنامه های سنجش عمق کرده اند. این شرکتها شامل غول نیمه هادی STMicroelectornics ، متخصص لیزر II-VI و ستاره در حال ظهور Lumentum (همچنین سازنده منبع لیزر در داخل Microsoft Kinect) است.
تولید کننده الگو نیز بسیار مهم است. الگوها به دو دسته فضایی یا زمانی تقسیم می شوند. اولین مورد از یک الگو و الگوریتم متفاوت برای مرتبط کردن تکه ای از پیکسل ها از تصویر مشاهده شده به الگوی مرجع برای محاسبه عمق استفاده می کند. دومی از الگوی متفاوتی در طول زمان برای رمزگذاری یک امضای زمانی منحصر به فرد استفاده می کند که می تواند در هر پیکسل مشاهده شده رمزگشایی شود. رویکرد مکانی برای مطابقت با الگوی ثبت شده و الگوی مرجع نیاز به محاسبات بیشتری دارد ، در حالی که رویکرد زمانی برای تطبیق نیاز به محاسبه کمتری دارد. از سوی دیگر ، سیستم نوری برای مولد الگوی فضایی نسبتاً ساده و کم هزینه است و یک عنصر نوری پراش ارزان (DoE) می تواند تمام الزامات را برآورده کند. با این حال ، یک مولد الگوی زمانی به یک سیستم نوری پیچیده مانند پروژکتورهای آینه ای مبتنی بر MEMS و سنسورهای سریع نیاز دارد. همچنین از حرکت رنج می برد ، که دامنه اندازه گیری آن را محدود می کند. برای تولیدکنندگان الگو ، بسیاری از شرکتها راه حل هایی مانند HiMax (ارائه DoE ، همچنین ارائه دهنده شایعه کننده DoE برای سنسور عمق در iPhone8) ، STMicroelectronics (پروژکتور میکروآینه MEMS که در Intel RealSense استفاده می شود) و Texas Instruments (ارائه DLP ثبت شده را ارائه می دهد) سیستم میکروآینه). دوربین سیستم نور ساختاری شبیه به یک دوربین معمولی RGB است ، با این تفاوت که نور مادون قرمز را حس می کند. محاسبه عمق بر اساس یک تصویر تحریف شده گرفته شده است. چندین شرکت نیمه هادی ، مانند STMicroelectronics و Texas Instruments ، راه حل های ساختاری دوربین نور را ارائه می دهند.
تصویر تحریف شده گرفته شده باید نرم افزار را برای ارزیابی بازیابی اطلاعات عمق بررسی کند. پیچیدگی نرم افزار به این بستگی دارد که آیا از یک الگوی روشنایی فضایی (نیاز به نرم افزار پیچیده) یا یک الگوی روشنایی زمانی (نیاز به نرم افزار ساده) در پروژکتور استفاده می شود یا خیر. شرکت های بزرگ مانند مایکروسافت و اینتل که سخت افزار سنجش عمق خود را با یکپارچه سازی تراشه های دیگر ارائه دهندگان ایجاد می کنند ، عموما دارای نرم افزار داخلی خود و حتی الگوریتم های خاص خود هستند (مانند HyperDepth توسط مایکروسافت). شرکتهای کوچک می توانند نرم افزار خود را بنویسند یا از نرم افزاری که شرکتهای نیمه هادی با یک کیت توسعه ارائه می دهند ، استفاده کنند.
زمان پرواز
یک سنسور معمولی ToF شامل منبع نور ، یک سیستم نوری است ، سنسور دوربین و پردازنده سیگنال. منابع نوری می توانند لیزری (برای کاربردهای با کارایی بالا) یا LED (برای برنامه های کم هزینه) باشند. سیستم نوری نسبتاً ساده است و شبیه دوربین های RGB معمولی است که میدان دید سیستم را تعیین می کند.
جالب ترین قسمت ToF سنسور دوربین آن است. سنسور دوربین آن نیاز به پردازش سیگنال منحصر به فرد در یک دامنه آنالوگ دارد و با سنسورهای دوربین RGB کاملاً متفاوت است. پردازش سیگنال آنالوگ معمولاً روی تراشه ای با پیکسل های حسگر یکپارچه می شود تا یکپارچگی سیگنال را تضمین کند. برای ToF با منبع نور پالس ، برای ضبط به مبدل زمان به دیجیتال (TDC) دقیق نیاز دارد.زمان سفر نور برای ToF با مدولاسیون ، برای محاسبه عمق ، به یک میکسر فوتون نیاز دارد تا اختلاف فاز بین نور منشاء و بازتاب شده را استخراج کند. علاوه بر این ، لغو پس زمینه نیز در محصولات خاصی برای افزایش عملکرد در محیط های روشن اجرا شده است.
بلوک های اصلی پردازش سیگنال آنالوگ نسبت به تراشه های حسگر نسبتاً جدید هستند. بازار حسگرهای ToF چند سالی است که داغ شده است زیرا از ToF برای سنسورهای مجاورت در بسیاری از گوشی های هوشمند رده بالا استفاده شده است. برای برنامه های تلفن همراه ، بسیاری از شرکت ها سنسورهای ارزان قیمت ToF مبتنی بر مدولاسیون را ارائه می دهند. به عنوان مثال ، STMicroelectronics یک سنسور باریک FoV ToF ارائه می دهد و Texas Instruments سنسورهای ToF را برای دید سه بعدی ماشین با یک FoV بزرگ می سازد. شرکت های دیگر از جمله Intersil و Melexis نیز ارائه دهنده حسگرهای ToF هستند. برخی از غول های اینترنتی نیز در حال ساخت (یا قصد ساخت) تراشه حسگر ToF خود برای پروژه های سخت افزاری خود هستند. به عنوان مثال ، مایکروسافت Canesta را در سال 2010 خریداری کرد و تراشه حسگر ToF خود را که در Kinect2 برای Xbox One استفاده می شد ، ساخت.
نرم افزار ToF نسبتاً ساده است. برخی از تولیدکنندگان تراشه حتی اطلاعات مستقیم از تراشه را بازخوانی می کنند.
آرایه دوربین

در حال حاضر از دوربین های دوگانه در بسیاری از دستگاه های هوشمند برای فعال کردن بسیاری از عملکردها ، به ویژه تشخیص عمق استفاده شده است.
پارامتر اصلی برای سیستم دوربین دوگانه ، فاصله بین دو دوربین دو دوربین در یک آرایه دوربین معمولی دوگانه که چندین سانتی متر از هم جدا شده اند فقط می توانند در فاصله بیش از 3 متر اندازه گیری کنند. برای اندازه گیری عمق میدان نزدیک (مانند دوربین های تلفن های هوشمند) ، این دو دوربین باید بسیار نزدیکتر به یکدیگر قرار گیرند. با این حال ، این دقت را در فاصله بیشتری فدا می کند.
پاناسونیک یک ساختار حسگر یک پیکسلی را پیشنهاد کرده است که پیکسل های دو دوربین در کنار یکدیگر روی یک تراشه قرار می گیرند و بنابراین عمق میدان نزدیک را می توان اندازه گیری کرد (~ 0.2 متر). با این حال ، این تکنیک همچنین به یک سیستم نوری سفارشی برای تراز دقیق دو پرتو نور با پیکسل نیاز دارد.

تراشه دوربین دوگانه نزدیک میدان توسط پاناسونیک.
یکی دیگر از تکنیک های رایج در بخش سخت افزار استفاده از دوربین های مختلف اما مکمل در آرایه دوربین است. به عنوان مثال ، یک دوربین RGB و یک دوربین سیاه سفید در بسیاری از سیستم های دوربین دوگانه استفاده می شود. این روش ضمن بهبود وضوح تصویر ، هزینه را کاهش می دهد (زیرا وضوح تصویر در دوربین سیاه و سفید بیشتر از دوربین RGB است) ، که این امر باعث افزایش عملکرد کلی سنجش عمق می شود. به طور کلی ، ارائه دهندگان راه حل های سخت افزاری برای دوربین های دوگانه مشابه تولید کنندگان دوربین RGB هستند ، مانند OmniVision (تراشه حسگر) ، سونی (تراشه حسگر) ، Sunny Optical (لنز) و بسیاری دیگر.
با این حال ، مهمترین بخش در آرایه دوربین هنوز نرم افزار است. همانطور که قبلاً نیز مورد بحث قرار گرفت ، یک الگوریتم قوی برای مطابقت نقطه در تصاویر ضبط شده برای تشخیص عمق آرایه های دوربین کلیدی است که به قدرت محاسبات زیادی نیاز دارد. شرکت های بزرگ در بازار گوشی های هوشمند مانند اپل و سامسونگ دارای تیم های نرم افزاری داخلی برای ایجاد الگوریتم های خود هستند. به غیر از آن شرکت های بزرگ ، چندین شرکت نرم افزاری نیز وجود دارند که IP نرم افزار را برای الگوریتم های تشخیص عمق آرایه دوربین ارائه می دهند. اینها شامل ArcSoft ، یک IP نرم افزار تلفن همراه با سابقه استشرکتی که راه حل های نرم افزاری را به غول های تلفن همراه مانند Vivo و Oppo و Corephotonics می فروشد ، که فقط با Omnivision همکاری کرده اند تا راه حل کامل دوربین دوگانه را ارائه دهند. طبق گفته وب سایت آنها ، به نظر می رسد که پروژه تانگو Google API نرم افزاری را برای پشتیبانی از درک عمق از سیستم دوربین دوگانه ارائه می دهد. چند سال آینده در حال حاضر ، بسیاری از فناوری های حسگر عمیق هنوز فضای زیادی برای پیشرفت دارند که می تواند فرصتی برای استارتاپ های فناوری باشد. علاوه بر این ، استارتاپ ها می توانند از فناوری سنجش عمق فعلی برای برنامه های نوظهور جدید استفاده کنند.
همه فناوری های سنجش عمق ، همراه با برنامه های CV:
سیستم های حساسیت عمق را می توان با رایانه فعلی ترکیب کرد برنامه های کاربردی چشم انداز تا عملکرد خود را تا حد زیادی افزایش داده و نیازهای استقرار در زندگی واقعی را برآورده سازد. این همچنین به کاهش اثرات موارد گوشه ای (شدید) کمک می کند - بسیاری از موارد گوشه ای در حالت دو بعدی در واقع موارد عادی در دنیای سه بعدی هستند! در نتیجه ، تشخیص عمق می تواند الگوریتم های CV را قادر سازد تا کارهای مهمتری را در زندگی ما انجام دهند ، که برخی از آنها حتی می توانند نوآوری های مخربی باشند که بازارهای دیگری را ایجاد می کند ، مانند تشخیص چهره.
حسگر ToF - استفاده از لیزر پالس با هزینه مناسب:
در حال حاضر ، سنسورهای ToF برای دستگاه های تلفن همراه به طور کلی از منابع نوری مبتنی بر مدولاسیون کم هزینه استفاده می کنند. همانطور که قبلاً بحث شد ، منبع نور مبتنی بر مدولاسیون دارای ابهام در محدوده است و عملکرد آن معمولاً از لیزر پالس پایین تر است. لیزرهای پالس با موفقیت در LiDAR استفاده شده اند ، اما هزینه ، مصرف برق و اندازه آنها هنوز برای دستگاه های تلفن همراه مناسب نیست. با این حال ، منابع لیزری در LiDAR اخیراً به سرعت در حال تکامل هستند. این امکان وجود دارد که استارتاپ ها لیزر پالس را به سنسورهای ToF موبایل برای سیستم های با عمق بالا و عملکرد بسیار حساس مانند AR و VR برای بخش های بازار الکترونیکی با مشاغل تجاری وارد کنند. این برنامه ها همچنین ممکن است حاشیه سود زیادی داشته باشند و فرصتی ایده آل برای استارتاپ ها است.
حسگر ToF- بهبود عملکرد LED:
در انتهای دیگر طیف سنسورهای ToF هزینه- برنامه های حساس مانند اینترنت اشیا برای دستگاه های ارزان قیمت ، لیزر هنوز گران است. LED می تواند در حسگرهای ToF برای برنامه های کم هزینه کار کند ، اما با کاهش عملکرد. مشکل عملکرد LED برای سنسورهای ToF را می توان در سطح دستگاه یا سیستم حل کرد. از دستگاه می توان از یک LED جدید با ظرفیت فرکانس مدولاسیون بالاتر استفاده کرد. از طریق سیستم ، استارتاپ ها می توانند از سیستم های ToF مبتنی بر LED استفاده کنند اما با عملکرد معادل لیزرها یا با بهبود مدار پردازش سیگنال آنالوگ ، با پیکربندی مجدد سیستم (یعنی استفاده از یک آرایه LED و ترکیب نتایج) ، یا با پیاده سازی یک الگوریتم جدید ارزیابی عمق. به منظور تحمل نور بیشتر از محیط ، چندین تکنیک لغو پس زمینه پیشنهاد شده است. به عنوان مثال ، در تراشه های حسگر ToF توسط STMicroelectronics ، یک سنسور نور محیط نیز به همراه پیکسل های سنسور عمق برای تخمین تداخل نور محیطی ادغام شده است. برخی از شرکت های دیگر نیز الگوریتم های لغو پس زمینه را در پردازش سیگنال (هم آنالوگ و هم دیجیتال) پیشنهاد کرده اند.
اما این راه حل هاکامل نیستند ارائه لغو حتی بهتر پس زمینه به ToF و نور ساختاری هنوز یک مسئله باز در فناوری سنجش عمق است. اگر استارت آپ ها بتوانند این مشکل را حل کنند ، ارزش آن بسیار زیاد خواهد بود ، به ویژه برای لغو پس زمینه که می تواند به سیستم های حسگر عمق نور ساختاری اجازه دهد در محیط های روشن کار کنند.
آرایه دوربین - برای وضوح بالا با ToF ترکیب می شود:
در حالی که سنسورهای ToF از وضوح پایین رنج می برند ، آرایه های دوربین وضوح خوبی دارند اما از مشکل تطبیق رنج می برند. با این حال ، این امکان وجود دارد که یک دستگاه هوشمند شامل هر دو آرایه دوربین و سنسور ToF باشد. همچنین می توان از آرایه های دوربین در برنامه های دیگری به جز تشخیص عمق مانند فوکوس هوشمند استفاده کرد. برای محاسبه نقشه عمق با وضوح بالا و دقت عمق خوب ، می توان اطلاعات هر دو آرایه دوربین و سنسورهای ToF را با هم ترکیب کرد. هزینه کل این سیستم سنجش عمق ممکن است حتی کمتر از سنسور ToF با وضوح بالاتر باشد.
اینها تنها چند مورد از فرصت های آتی برای برنامه های جدید بینایی رایانه ای با سنسورهای عمق است. تا کنون ، اکثریت قریب به اتفاق برنامه های بینایی کامپیوتری شامل تفسیر جهان دو بعدی از طریق دوربین بودند. با استفاده از سنسورهای عمق ، ما ابعاد کاملی از داده ها را به رایانه ها می دهیم و امکان کارکرد رایانه ها را بسیار افزایش می دهیم. :
نظریه هرج و مرج ، اثر پروانه ای ، و نقص رایانه ای که همه چیز را آغاز کرد
 یک سیستم آشفته سیستمی است که در آن تغییرات فوق العاده جزئی در شرایط اولیه (آبی و زرد) منجر به رفتار مشابه می شود برای مدتی ، اما این رفتار پس از مدت نسبتاً کوتاهی متفاوت می شود. (Hellisp از Wikimedia Commons/ایجاد شده توسط XaosBits با استفاده از Mathematica و POV-Ray)
یک سیستم آشفته سیستمی است که در آن تغییرات فوق العاده جزئی در شرایط اولیه (آبی و زرد) منجر به رفتار مشابه می شود برای مدتی ، اما این رفتار پس از مدت نسبتاً کوتاهی متفاوت می شود. (Hellisp از Wikimedia Commons/ایجاد شده توسط XaosBits با استفاده از Mathematica و POV-Ray) نظریه هرج و مرج ، اثر پروانه ای ، و نقص رایانه ای که همه چیز را آغاز کرد
قرن ها فکر می کردیم که جهان کاملاً قطعی بود. اما حتی اگر همه قوانین را بدانید ، نمی توانید از شر هرج و مرج خلاص شوید.
همانطور که باب دیلن به طور مشهور می خواند ، "شما نیازی به متخصص هواشناسی ندارید تا بدانید باد از کدام طرف می وزد." با این حال اگر…