یک هفته بینایی رایانه ای در سئول: نکات برجسته ICCV 2019 من
یک هفته بینایی رایانه ای در سئول: نکات برجسته ICCV 2019 من
توجه: از همه کسانی که نظر دادند و تغییرات را در پیش نویس اصلی این پست پیشنهاد کردند ، متشکریم. نکات برجسته نسبت به علایق کنونی من در زمینه بازیابی اطلاعات در ویدئوهای زنده بزرگ مقیاس دارد.
من فکر می کنم ICCV2019 یکی از بهترین کنفرانس هایی بود که تا کنون حضور داشته ام. برخی از دوستان من حتی گفتند که آن را بهتر از CVPR امسال دوست دارند. دیدن همه پیشرفت ها در بینایی رایانه بسیار زیبا بود. همچنین ، سئول یک شهر فوق العاده است که مطمئناً دوباره از آن دیدن خواهم کرد.
اگر بخواهم 3 مورد متداول ترین موضوعی را که دیدم ذکر کنم ، می گویم فشرده سازی/تقویت ، جستجوی معماری عصبی و ردیابی افراد کارهای مرتبط (شناسایی مجدد شخص/چهره ، شمارش جمعیت و غیره). با احترام به GAN ها که هنوز هم بسیار محبوب هستند.
از طرف دیگر ، اگرچه از پیشرفت همه جانبه در پردازش ویدیو در سال جاری خوشحال شدم ، اما نتوانستم در مورد مقیاس پردازش ویدیو اطلاعاتی کسب کنم. شاید این کار برای کارهای بعدی باقی مانده است. با این اوصاف ، برخی از نکات برجسته من در اینجا آمده است.
برطرف کردن فاصله Sim-to-Real در معیارهای چشم انداز کامپیوتر
نظر Karpathy در مورد تفاوت بین تحقیقات بینایی رایانه ای در دانشگاه و صنعت و نحوه برای از بین بردن شکاف. برای پیشرفت در تحقیقات یادگیری ماشین برای وسایل نقلیه خودران. همچنین من از نوع جدید معیار پیشنهادی او برای صنعت خوشم می آید: آزمونها »به جای معیارها
در اینجا یک نقل قول عالی دیگر در زمینه تکرار در داده های آموزش و آزمایش به جای تمرکز تنها بر روی مدلها وجود دارد:
بخشی از محلی سازی مجدد بخشی از صحبت های تورستن ساتلر در آموزش محلی سازی بصری.
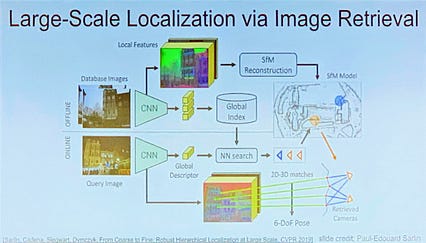 بازیابی تصویر (همان فناوری که برای جستجوی تصویر استفاده می کنیم) برای محلی سازی در نقشه ها بسیار خوب عمل می کند.
بازیابی تصویر (همان فناوری که برای جستجوی تصویر استفاده می کنیم) برای محلی سازی در نقشه ها بسیار خوب عمل می کند. بخش تشخیص عمل از صحبت های جیتندرا مالیک

صحبت های پروفسور مالیک مرا کنجکاو کرد تا درباره شبکه های SlowFast آنها با جزئیات بیشتر بخوانم. در اینجا قسمتی است که او نشان می دهد شبکه های SlowFast می توانند جریان نوری مانند ویژگی ها را بدون برآورد جریان نوری گرانقیمت
ارائه شفاهی ما
پوسترها
DecptionNet: تصادفی سازی دامنه شبکه محور یکی از موارد مورد علاقه من بود. بیشتر برای مفهوم افزایش خودکار داده ها برای آموزش. من با وادیم و سرگی صحبت کردمدر مورد راه های ممکن برای گسترش این رویکرد در حوزه های دیگر و اینکه چگونه می توان به طور خودکار کشف کرد که کدام تغییرات برای DeceptionNet مناسب هستند. در حال حاضر به تخصص دامنه متکی است.
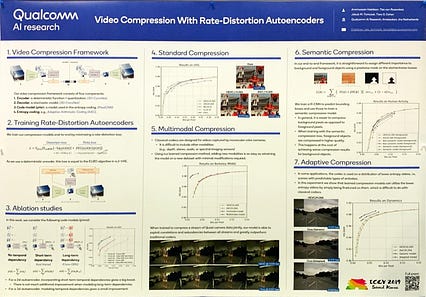
این یکی است از نمایندگان مورد علاقه من در مقاله های فشرده سازی ویدئویی که دیدم. فشرده سازی ویدئو با رمزگذارهای خودکار Rate-Distortion: روی کل حجم ویدیو با پیچیدگی های سه بعدی به جای روش "پیدا کردن فریم های کلیدی ، رمزگذاری تفاوت ها" کار کنید. من فکر می کنم آنها هنوز در مورد مقیاس پذیری سایر روش های فشرده سازی ویدئوی شبکه های عصبی همان مشکلات را دارند وقتی که ما در مورد مقیاس ویدیوی YouTube/Twitch صحبت می کنیم ...
همچنین ارائه شفاهی ما در مورد بررسی محدودیت های شبیه سازی رفتار برای رانندگی خودکار بود.


























